How many move / mkdir / delete operations are in a single sync run - expected average …?
Let us understand if bundling for other operations than put will really improve sync, right?
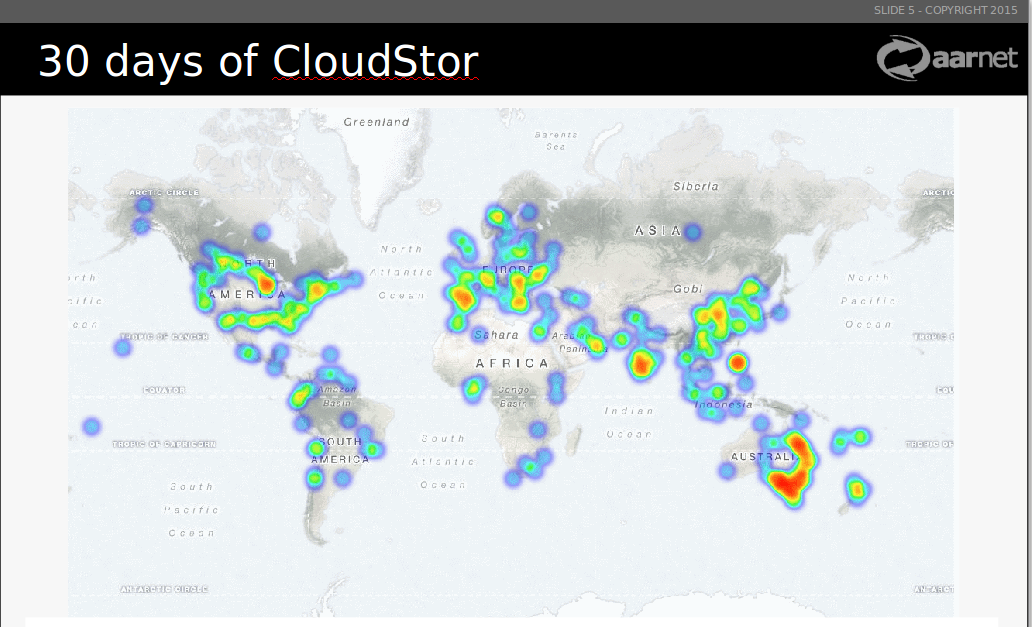
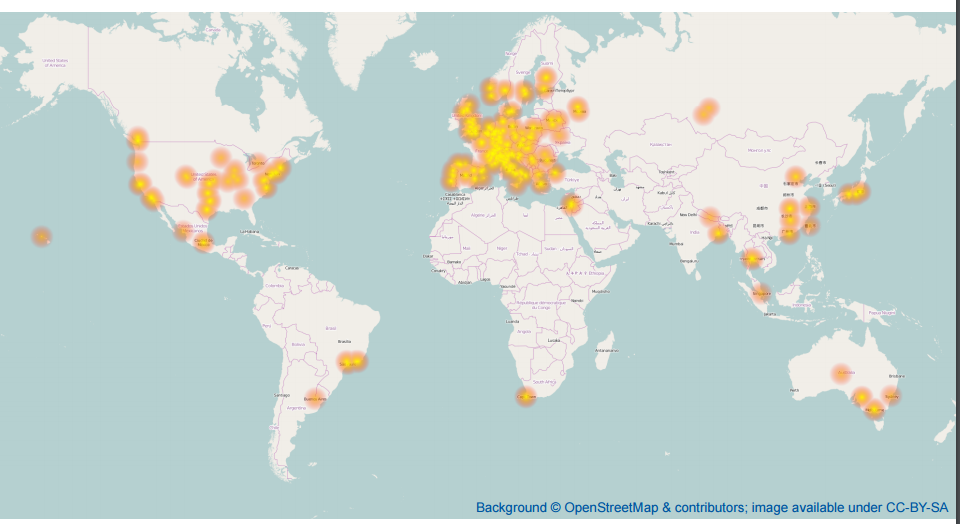
These are only the data about PUT and GET operations, I think I will ask our biggest customers about some more detailed characteristics about PUT/GET/DELETE/MOVE oeprations, how often do they do that and so one. I also included some geolocations of users, since bundling makes extreme sense for big latencies.
Some statistics also about operations at CERN, what you can find on http://cs3.ethz.ch/ :
The client currently calculates a list of operations for every sync run, right?
We could use a single bundle containing the sync operations in order as they have been calculated?
We still want like 2-4? parrallel connections?
Does the current implementation bundle all CREATION PUT requests? Or does it create eg. a bundle per dir?
What is the reason for not bundling the UPDATE PUT requests?
Obviously, as you already stated above MOVE and MKCOL need to come before PUT and DELETE.
Why do you want to abert on DELETE errors? Id say it depends on the error. If the resourca is already gone we can ignore the error. on a 500 we should stop the sync but I’d leave 500 out of the expected sync operations. If a PUT fails we should collect the errors and return a list of each cause. Again, depending on the error type we need to decide if we can continue or not. I currently cant think of an error thet would let us continue, Out of Quota maybe …
In any case lets do this step by step. Having bundles for CREATE PUT is already a huge step forward.
Now, regarding multipart/mixed / multipart/related. While multipart/related would allow us to describe the whole sync we would have to invent eg. a content type containing information about binary blobs, like RFC 2387 - The MIME Multipart/Related Content-type or RFC 2387 - The MIME Multipart/Related Content-type. Reading through the spec it looks better suited to bundle multiple resources that can be aggregated to a single resource that can then be rendered. I looks a little fragile when one of the resources is broken / corrupted eg, during transmission.
multipart/mixed would require us to add headers for the target directory, eg. “Content-Location”. I think we don’t necessarily need to add an X-OC-METHOD to each body part, because at least currently we are bundling only CREATE PUT operations. We could also add UPDATE PUT without needing to give a X-OC-METHOD. We could even say that multipart/mixed body parts derive the destination from the request so an upload of images to the same folder does not need any additional headers in the body parts.
Since we require to execute MOVE/MKCOL before any PUT / DELETE we can bundle them together as well. mkdir in ownCloud is always recursive so the four bundles in order are MKCOL, MOVE, PUT, DELETE. Each could be contained in a separate multipart/mixed request. We could start a new bundle to execute operations on a different directory to save the ‘Content-Location’ header … Then again I dont think we can gain a lot … because the new request also contains a ton of other headers…
So … no need to invent headers for multipart/mixed I think.
The client currently calculates a list of operations for every sync run, right?
Yes, in the current bundle implementation sync client segregates the operations in the directories order:
So that All MOVE/MKDIR/PUT operations will be done per directory and will finish before any POST bundle job will be started.
When it is finished, it means all the big files(we want big files to be synced first) and preconditions are satisfied, so that we can continue with small files. You are bundling them into multipart/mixed requests in 5 parallel flows and send. In current implementation it is cross-directory since all the preconditions are being satisfied. This has once clear advantage. It is very easy to document and present the logic. It is also extremely easy to implement it on the server, since server just checks the paths, methods and then executes the proper operations. You have a single endpoint to do that. Headers overhead will be neglible, since anyways in separate requests you would need to insert this information somehow.
I think segregation per directories makes sense only for preconditions and maybe for DELETE DIR jobs. It makes no sense for UPDATE/CREATE jobs, and there the only limitation will be how many files and how big bundle could be per request. This way you could optimize it with dynamic chunking and http/2.
Hmm, I think you might be right. It makes no sense to abort everything there. I think interesting approach could be a DELETE multipart request header Content-Location, so that you delete the files per directory. The parts inside multipart are the names of the files in the directory then. But anyways, you need to insert the names of the files in the header of part.
Since we require to execute MOVE/MKCOL before any PUT / DELETE we can bundle them together as well. mkdir in ownCloud is always recursive so the four bundles in order are MKCOL, MOVE, PUT, DELETE. Each could be contained in a separate multipart/mixed request. We could start a new bundle to execute operations on a different directory to save the ‘Content-Location’ header … Then again I dont think we can gain a lot … because the new request also contains a ton of other headers…
So … no need to invent headers for multipart/mixed I think.
I would not do that. If MKCOL fails, you just transported 10MB of data for nothing. There is need for 3 separate multipart messages. (Preconditions, Transfers, Deletes). As stated before, this way you could very clearly define your sync in 3 stages. So that e.g. Preconditions are done per directory, Transfers cross-directory and Deletes per directory.