gabbi7
September 19, 2016, 8:32pm
1
Hi,
I’m a student and PHP developer from Slovakia (Central Europe). As my master thesis project I chose to improve the ownCloud sync process. As I’ve read some time ago, ownCloud always syncs the whole modified file and not only the different parts of the file.
My questions for more experienced ownCloud developers are:
Do you think it’s possible to improve the file sync process? If so, do you think diff synchronisation is the right thing to do?
Where (in the code) is the file synchronisation algorithm implemented?
Thanks.
1 Like
mrow4a
September 19, 2016, 8:55pm
2
Development of ownCloud sync performance optimization is currently oriented on bundling multiple small files create/update/mkdir/move/delete into bundled requests. This makes sense for synchronisation of many small files in one sync or in the sync over the bigger latency. This work is currently in progress on both client and server side. You can read about that here:
I want to create a prototype app for bundling support on both server and the client. The idea behind the bundling is to have one PHP process handling creation/update of the files on the server, instead of separate PUT requests for each file.
I am using a word prototype, since I wanted to veryify the design with extended smashbox framework which is also now in prototype phase.
Here are some specifications:
POST request coming from client side will trigger one PHP process, which will handl…
The above improvement is called Bundling. If you are interested, I could append you a presentation I did about that for ownCloud conference. It is already implemented and under the tests now. This way you could have a sense on how to make a improvement to the sync algorithm.
About the improvement you are talking about, it is called Delta Sync. However, it is not easy to find a use case for delta sync, since e.g. documents are xml basicaly, it means each time you change them, their content is changing. It is nearly impossible to find a case for a file that deltasyncing will make sense (and it is very expensive)
What we are currently looking at, is to implement improvement called Dynamic Chunking (Dont mess up with deduplication using dynamic chunking). Basicaly, concept is that, in current implementation big files e.g. 100MB are being chunked into smaller pieces called 10MB chunks. The problem here is that this is fixed value, and it is not appropriate on all types of the networks (WiFi versus FiberToTheHome versus LAN). For WiFi it makes sense for small chunks, while for fast networks, it makes sense to have very big chunks.
I am not sure how familiar are you with TCP, but there the concept it is the same. It is called Additive increase/multiplicative decrease (AIMD) congestion control. This behaviour is also called Probing For Bandwidth,
TCP congestion control - Wikipedia
I would look for something similar, but for synchronisation of files.
mrow4a
September 19, 2016, 9:13pm
3
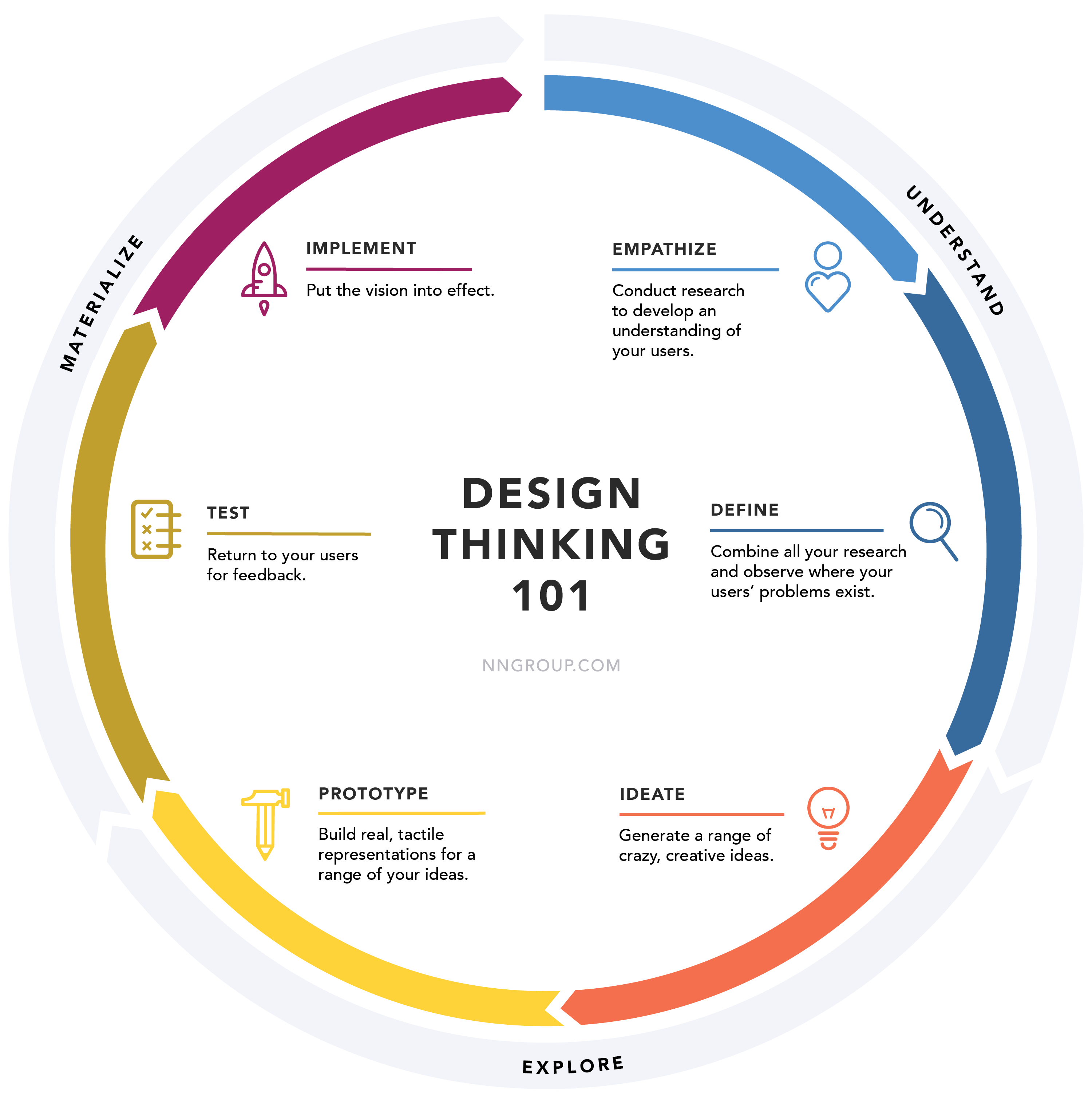
Summarizing above thing, you should not focus on improving sync by definition. The improvement should follow Design Thinking paradigm.
Starrt from Empathize, not Implement :>
A longer discussion about delta syncing is available at the client issue tracker. The largest use case for most people requesting such a delta sync where backups, videos, truecrypt containers and so on.
opened 07:04PM - 14 Dec 12 UTC
closed 07:55AM - 23 Jul 18 UTC
Enhancement
Performance
bounty
In Dropbox, there notes that only the file changes are sync-ed, not the entire f… ile. https://www.dropbox.com/help/8/en. It is great if ownCloud can do the same. Especially for large files, sync-ing the entire files make a lot of bandwidth and time unnessararily wasted.
In my testing with latest 4.5.4 and sync client in Ubuntu 12.04, I prepared a 1GB text file, append a few characters to the end, and monitor the traffic and the file in the server, I see the entire 1GB file is transffered to the server and the server is actually creating a new file.
A reply from the forum indicates that librsync has this feature http://librsync.sourceforge.net/, maybe the csync can be switched to the libsync.
1 Like
mrow4a
September 20, 2016, 7:08am
5
@gabbi7 If you want to give it a try, read all the conversations at ownCloud about that and get the list of candidates (file types) for delta sync, along with granuality of the delta e.g. 10% file size hashes.
You will need to add this to capabilities on the server the same way I did it for bundling (this is why I mention please have a look on my job, since I did same thing)
master ← bundling_plugin
opened 03:45PM - 10 Aug 16 UTC
Update 16 Nov 2016:
Research of performance of cloud synchronization services l… ike ownCloud, Seafile and Dropbox
has shown, that on-premise services show better performance characteristics than public clouds
syncing big files (higher transfer rates in both upload and download could be obtained due to simple
implementation and smaller activity of users for specific bandwidth) and are very competitive
syncing mixtures of files.
Unlike typical web services, cloud sync and share is characterized by requests load/number much outreaching the typical loads to the web server per user in some specific activity type.
Underutilized upload/download bandwidth and long distribution tails (penalizing transfers
of small files over WAN) are characteristic for services using current ownCloud synchronization
protocol. Important factor in synchronization performance is also number of operations performed
per single-file request on the web-server. Along with http/2 extensions - which will be addressed separately - this feature should reduce the impact of latency and significantly lower number of requests to the server, making server more lightweight, utilize pipe better and in turn sync files faster.
With 0 latency, having sync on local machine, the following scenario has been under the test (in this scenario latency/locality is much favourising traditional http/1 puts):
https://s3.owncloud.com/owncloud/index.php/s/kSVQvr3y7EdmZ6b?path=%2F
1000f of 1kB and 100f of 100kB - total 11MB.
Number of requests has been reduced from 1100 to 15 requests (typical number for web content)
Sync time on the test machine has been reduced, on average, from 37s to 31s (taking also into account recent sync performance improvement for single puts in the folder, which bundling improved out of the box from concept https://github.com/owncloud/client/pull/5230, https://github.com/owncloud/client/pull/5274)
This is profile for 1 ( ONE! ) PUT of 22kB file using standard http/1:

This is profile for 1 ( ONE! ) Bundle containing 10 (TEN) 22kB files - total 220kB using standard http/1:

Bundled request requirements
> 1. A bundle Request receives a 207 Multi-Status Response with the individual 20x, 30x, 40x, 50x statuses for each file. It receives a 400 Bad Request response with an error message if the Request was malformed.
>
> 2. Request body can be any mime-type, with full implementation freedom.
>
> 3. Request is finishing with delivering last part of successfull response after all linked operations has been successfuly finished, or aborted immedietaly in case of request cancelation/termination.
>
> 4. If request cannot be executed or response cannot be correctly constructed, request has to be aborted and error 4xx-5xx has to be returned for whole the request.
We already had implemented both prototypes for multipart/mixed and multipart/related, discussed it a lot and tried out:
I found following limitations for each of the request, starting with the order of implementation:
Multipart/related:
- This type of mime type includes in the first part the list of files to be created, in the key->value manner, where key is the path and value is metadata for that file. Response is created based on the keys in the metadata part, and files are reconstructed from binary contents in the request body, referenced by Content-ID
- This mime-type allows to to easily return response for the file, because key-value structure and validation at the begining allows you to correctly construct the response for each of the keys-files(even if content-id is missing, you can return the response for the specific file that binary content for that file has not been found) or return parsing error at the begining.
- This is high performance solution, where files are being added to OC as they are being read from the request body and allows you to use chunked transfer encoding for the response while files are being added.
- Disadvantage is that list of files is specified in the first part, and the binary contents are anynomous reading the request without first part.
- Disadvantage is that, in case of parsing error, request has occupied bandwidth for nothing - this should however not happen in practice.
Multipart/mixed:
- This mime types includes in each part headers (metadata for a file), and in the part body, the actual file body.
- As in multipart/related, we can use chunked transfer encoding for the response.
- Advantage here is that reading pure request, we have an independent parts in the request.
- This mime-type requires you to parse the request body on fly in order to read the body of the request and simultaneously add it to OC. In order to correctly construct the response for each of the files, each part has to be parsed and validated, since it serves as a container for the file.
- In this mime-type, in order to validate the request at the beginning, one would need to parse the request body and save it in-memory or on the disk. The other option is to seek in the request body, however this is dangerous and unpredictable. This results in the fact, that the bundle has to occupy in the peak moment the memory equal to chunk size - typicaly 10MB for request itself and 10MB for in-memory storage, and will decrease with each file added to OC. This gives 20MB per request, and 20GB per 1000 simultaneous request in peak moment.
- In this mime-type in one need to validate and parse independent parts on fly. In case of single part parsing error, one would need to raise the full request error, since the construction for that file might not be possible due to lacking URL header for that file, which will result in lack of the response of the previous files already added in the OC for that bundle. Having half of the files acknowledged for that request, and afterwards return error for the whole request invalidates the architectural concept for request in OC (refer to point 3 and 4).
- Disadvantage is that, in case of parsing error, request has occupied bandwidth for nothing - this should however not happen in practice.
The implementation will follow the multipart/related in this version.
- [x] Bundle feature passes prove of concept tests
- [x] Integrated error handling
- [ ] Full unit tests coverage
- [ ] Documentation
master ← bundling_plugin
opened 03:45PM - 10 Aug 16 UTC
Update 16 Nov 2016:
Research of performance of cloud synchronization services l… ike ownCloud, Seafile and Dropbox
has shown, that on-premise services show better performance characteristics than public clouds
syncing big files (higher transfer rates in both upload and download could be obtained due to simple
implementation and smaller activity of users for specific bandwidth) and are very competitive
syncing mixtures of files.
Unlike typical web services, cloud sync and share is characterized by requests load/number much outreaching the typical loads to the web server per user in some specific activity type.
Underutilized upload/download bandwidth and long distribution tails (penalizing transfers
of small files over WAN) are characteristic for services using current ownCloud synchronization
protocol. Important factor in synchronization performance is also number of operations performed
per single-file request on the web-server. Along with http/2 extensions - which will be addressed separately - this feature should reduce the impact of latency and significantly lower number of requests to the server, making server more lightweight, utilize pipe better and in turn sync files faster.
With 0 latency, having sync on local machine, the following scenario has been under the test (in this scenario latency/locality is much favourising traditional http/1 puts):
https://s3.owncloud.com/owncloud/index.php/s/kSVQvr3y7EdmZ6b?path=%2F
1000f of 1kB and 100f of 100kB - total 11MB.
Number of requests has been reduced from 1100 to 15 requests (typical number for web content)
Sync time on the test machine has been reduced, on average, from 37s to 31s (taking also into account recent sync performance improvement for single puts in the folder, which bundling improved out of the box from concept https://github.com/owncloud/client/pull/5230, https://github.com/owncloud/client/pull/5274)
This is profile for 1 ( ONE! ) PUT of 22kB file using standard http/1:

This is profile for 1 ( ONE! ) Bundle containing 10 (TEN) 22kB files - total 220kB using standard http/1:

Bundled request requirements
> 1. A bundle Request receives a 207 Multi-Status Response with the individual 20x, 30x, 40x, 50x statuses for each file. It receives a 400 Bad Request response with an error message if the Request was malformed.
>
> 2. Request body can be any mime-type, with full implementation freedom.
>
> 3. Request is finishing with delivering last part of successfull response after all linked operations has been successfuly finished, or aborted immedietaly in case of request cancelation/termination.
>
> 4. If request cannot be executed or response cannot be correctly constructed, request has to be aborted and error 4xx-5xx has to be returned for whole the request.
We already had implemented both prototypes for multipart/mixed and multipart/related, discussed it a lot and tried out:
I found following limitations for each of the request, starting with the order of implementation:
Multipart/related:
- This type of mime type includes in the first part the list of files to be created, in the key->value manner, where key is the path and value is metadata for that file. Response is created based on the keys in the metadata part, and files are reconstructed from binary contents in the request body, referenced by Content-ID
- This mime-type allows to to easily return response for the file, because key-value structure and validation at the begining allows you to correctly construct the response for each of the keys-files(even if content-id is missing, you can return the response for the specific file that binary content for that file has not been found) or return parsing error at the begining.
- This is high performance solution, where files are being added to OC as they are being read from the request body and allows you to use chunked transfer encoding for the response while files are being added.
- Disadvantage is that list of files is specified in the first part, and the binary contents are anynomous reading the request without first part.
- Disadvantage is that, in case of parsing error, request has occupied bandwidth for nothing - this should however not happen in practice.
Multipart/mixed:
- This mime types includes in each part headers (metadata for a file), and in the part body, the actual file body.
- As in multipart/related, we can use chunked transfer encoding for the response.
- Advantage here is that reading pure request, we have an independent parts in the request.
- This mime-type requires you to parse the request body on fly in order to read the body of the request and simultaneously add it to OC. In order to correctly construct the response for each of the files, each part has to be parsed and validated, since it serves as a container for the file.
- In this mime-type, in order to validate the request at the beginning, one would need to parse the request body and save it in-memory or on the disk. The other option is to seek in the request body, however this is dangerous and unpredictable. This results in the fact, that the bundle has to occupy in the peak moment the memory equal to chunk size - typicaly 10MB for request itself and 10MB for in-memory storage, and will decrease with each file added to OC. This gives 20MB per request, and 20GB per 1000 simultaneous request in peak moment.
- In this mime-type in one need to validate and parse independent parts on fly. In case of single part parsing error, one would need to raise the full request error, since the construction for that file might not be possible due to lacking URL header for that file, which will result in lack of the response of the previous files already added in the OC for that bundle. Having half of the files acknowledged for that request, and afterwards return error for the whole request invalidates the architectural concept for request in OC (refer to point 3 and 4).
- Disadvantage is that, in case of parsing error, request has occupied bandwidth for nothing - this should however not happen in practice.
The implementation will follow the multipart/related in this version.
- [x] Bundle feature passes prove of concept tests
- [x] Integrated error handling
- [ ] Full unit tests coverage
- [ ] Documentation
On the client, we are already aware which file are NEW, and which files are to UPDATE:
master ← bundling_plugin
opened 05:49PM - 05 Sep 16 UTC
- [x] Client feature is able to create bundled INSTRUCTION_NEW request.
- [x] Bu… ndle could contain only file which is smaller than chunking size
- [x] Bundle may contain only files with total is smaller than chunking size
- [x] Bundle is compatibile with https://github.com/owncloud/core/pull/25760
- [x] Bundle correctly adds the files to both remote and local database - checked by manual tests
- [ ] Bundle correctly adds the files to both remote and local database - checked by unit tests
- [ ] Bundle correctly adds the files to both remote and local database - checked by integration tests
- [x] Bundle passes prove of concept tests
- [ ] Integrated error handling
- [x] Boundary generator
- [ ] Add support for Upload Device to limit bandwidth usage
master ← bundling_plugin
opened 05:49PM - 05 Sep 16 UTC
- [x] Client feature is able to create bundled INSTRUCTION_NEW request.
- [x] Bu… ndle could contain only file which is smaller than chunking size
- [x] Bundle may contain only files with total is smaller than chunking size
- [x] Bundle is compatibile with https://github.com/owncloud/core/pull/25760
- [x] Bundle correctly adds the files to both remote and local database - checked by manual tests
- [ ] Bundle correctly adds the files to both remote and local database - checked by unit tests
- [ ] Bundle correctly adds the files to both remote and local database - checked by integration tests
- [x] Bundle passes prove of concept tests
- [ ] Integrated error handling
- [x] Boundary generator
- [ ] Add support for Upload Device to limit bandwidth usage
You would need to create new job DeltaUpload, which will first do GET to server DeltaSync Plugin, giving you list of hashes at specific granuality for a specific file, and while you get it, you do hashing also on the client. If you see that there is no particular change or change is not exceeding 50% of the file, you continue with normal Upload. If change is smaller than a threshold (this should be obtained also in capabilities), you continue with deltasync
When asynchronously it is finished, you continue and do POST/POSTs(since file can be chunked).Multipart saying what file and what offset to update.
master ← bundling_plugin
opened 05:49PM - 05 Sep 16 UTC
- [x] Client feature is able to create bundled INSTRUCTION_NEW request.
- [x] Bu… ndle could contain only file which is smaller than chunking size
- [x] Bundle may contain only files with total is smaller than chunking size
- [x] Bundle is compatibile with https://github.com/owncloud/core/pull/25760
- [x] Bundle correctly adds the files to both remote and local database - checked by manual tests
- [ ] Bundle correctly adds the files to both remote and local database - checked by unit tests
- [ ] Bundle correctly adds the files to both remote and local database - checked by integration tests
- [x] Bundle passes prove of concept tests
- [ ] Integrated error handling
- [x] Boundary generator
- [ ] Add support for Upload Device to limit bandwidth usage
master ← bundling_plugin
opened 05:49PM - 05 Sep 16 UTC
- [x] Client feature is able to create bundled INSTRUCTION_NEW request.
- [x] Bu… ndle could contain only file which is smaller than chunking size
- [x] Bundle may contain only files with total is smaller than chunking size
- [x] Bundle is compatibile with https://github.com/owncloud/core/pull/25760
- [x] Bundle correctly adds the files to both remote and local database - checked by manual tests
- [ ] Bundle correctly adds the files to both remote and local database - checked by unit tests
- [ ] Bundle correctly adds the files to both remote and local database - checked by integration tests
- [x] Bundle passes prove of concept tests
- [ ] Integrated error handling
- [x] Boundary generator
- [ ] Add support for Upload Device to limit bandwidth usage
I would first give a try only with big files, which are already chunked, so that you actualy do delta sync on chunks :>
3 Likes
Klaas had a blog article on that a while ago. You already got other tips.
Looking forward to hear more from you!
mrow4a
October 15, 2016, 5:28pm
7
About deltasync in ownCloud on CS3 conference last year:
I hope this feature gets added
mrow4a
December 2, 2016, 10:24am
9
@konkwest It is under formal protocol specification and consultation with customers now.