is it normal, that my ocis is using a huge amount of memory after some uptime?
I never saw this on the old PHP Variant, but i also never hosted any GO application before, so i wanted to ask
here you can see what i mean: https ://ocis.mb.msrtg.de/s/AbeDIxTzLajBTrd
ocis has been setup using default systemd-instructions on a Debain 11 vServer.
Hard to say. Does it continue to grow? If not you might just be seeing “normal” behavior of the go garbage collector. It might be worth to fiddle around with GO’s GOGC and GOMEMLIMIT settings if you want to limit the memory usage. Both settings influence the behavior of the go runtime’s garbage collector. The default behavior of the garbage collector can lead to high memory usage for longer periods of time for certain workloads. (For details see e.g.: A Guide to the Go Garbage Collector - The Go Programming Language)
Ahhhh, thanks a lot for the explanation.
i also thought i should have explained the environment little better
I currently have 2 users, approx 8 devices, not all online all the time, and mostly some photos or textfiles per day beeing shared. in the past there were more users on my php installation, but it did not migrate them all yes, as there are two independat groups.
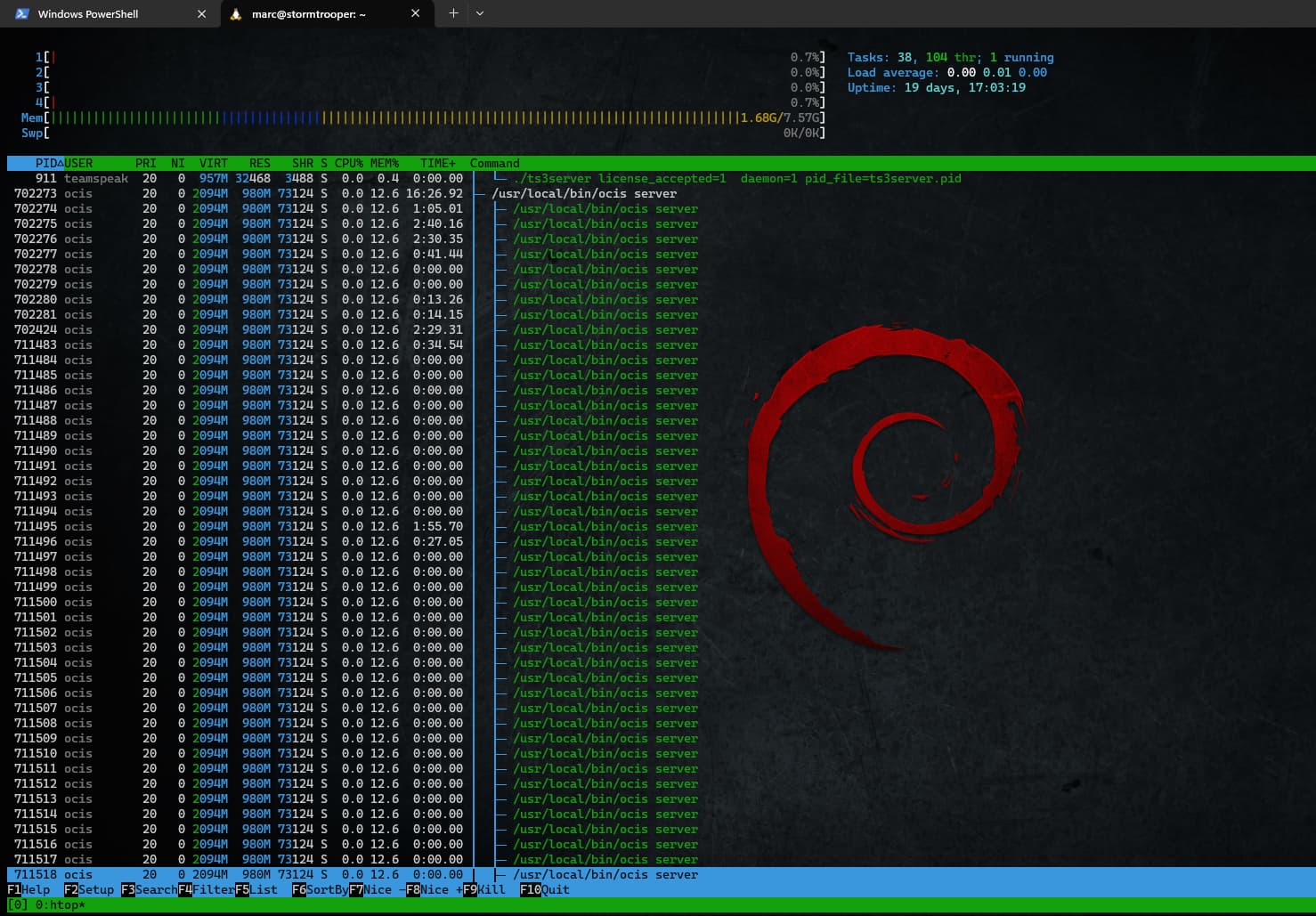
to answer your question: yes the usage seems to be increasing. it starts arround 4% if i restart the service.
sometimes, uploading a bunch of photos from one smartphone will bring it near 100%. Then it seems to crash and jumps back to single-digit usage again.
However autolimit seem to explain this perfectly to my understanding. Will try to adjust the environment in my systemd-service to include gomemlimit and keep observing it
Indeed, but beeing sysadmin for about 15 years now, this is hard to exactly describe, as i did not keep the logs from that moment.
i just remeber getting an error message on my phone “upload failed” while seeings some error in “journalctrl -f -u ocis” and afterwars the memory usage in htop was back to initial values and the app on my mobile just retried the upload succesfull.
anyway, i think the most important update right now:
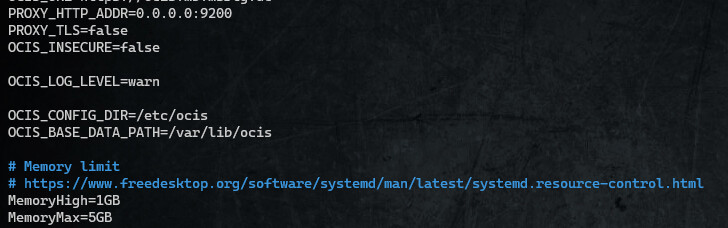
I’ve read a little bit through: https ://www.freedesktop.org/software/systemd/man/latest/systemd.resource-control.html and updated my ocis.enc accordingly:
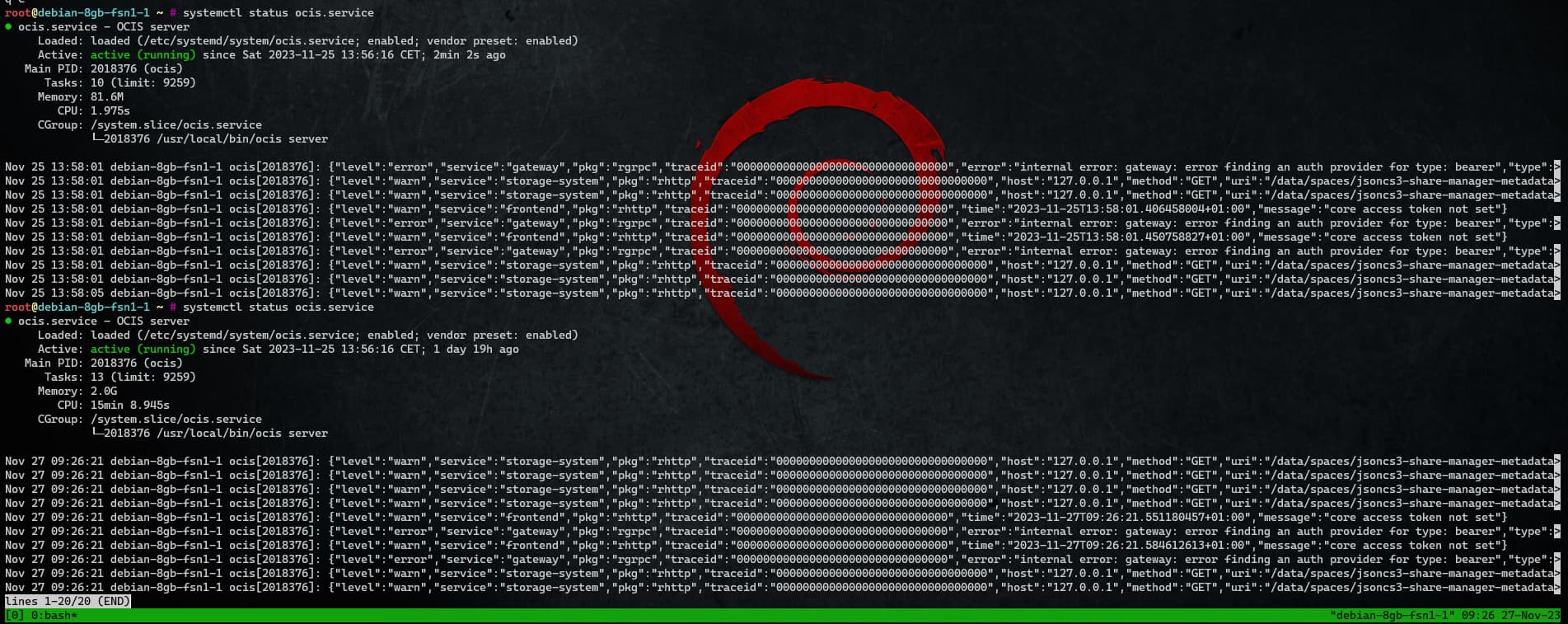
Since then i never saw more than some % memory usage on the ocis service.
Feels for me, as if the GC would not start before the physical limits of the machine are reached, while it is keeping the memory free now every now and then.
And this is exactly the behaviour i’d hope for
Will observ this now and write an update if i learn new facts
Thanks a lot for the inital explanantion keywords for my research
Kind regards
Marc
I’m encountering the same issue with OCIS. After about 7 days of up time, OCIS container consume all the available RAM and swap, causing extreme slow down of the server. What is the right way to go about solving this issue? I probably can setup a cron job to restart everyday but that is rather silly.
@ethanauroria I agree using a cronjob to restart is ocis is silly and should not be done.
Can you try setting memlimits as @endstille described?
Also, when ocis consumes all the ram and swap, will it go back to normal? Or does it continue to consume until you kill it? Can you maybe share some logs from when this happens?
Unfortunately I’m using the docker setup without logging to a mount point. What happened was that it took up all available RAM and swap space, and then never released any memory. I forcefully reboot the entire server as things grinded down to a halt I could not even restart just the containers.
About the memlimits thing, I probably need to wait and see how it goes. It seems to happen only after about a week or so of up time.
hmmm, sorry for the question, but how would i do that?
the server is Debain 11 (was 10 and 9 before) and was / is hosting my ownCloud 10 instance.
i followed the systemd-guide to setup oCIS and migrated my users and data manually.
i think i have to adjust the .env file to exclude the thumbnail service? i can try it.
update after some days of uptime, the memory is slightly higher than in the beginning.
I have the impression, that it as related to uploads from my mobile.
I also always get errors there “file not found in local filesystem” or smililar, also the file are in fact transfered to the cloud perfectly fine. i asume it is failing, then retrying independantly but keeping the error popup open.
PS: OnePlus8T with up-to-date OxyOS is running on my mobile.
You can set that in the enviromentvariable OCIS_EXCLUDE_RUN_SERVICES. Then the services mentioned there will not start.
Regarding the file not found in local filesystem happens here too when I delete the files immediately after taking the photo. The client will pickup the filename from android anyway, tries to upload it but can´t find it. This should not affect the server in any way.
Thanks a lot!
I’ve now added the following to my ocis.env and restarted the service.
OCIS_EXCLUDE_RUN_SERVICES=“thumbnails”
Before it was running at roughly 16% memory, sometimes 23%.
about two days later it climbed again from about 3-5% mem usage in the beginning to 12%, so i assume thumbail service is not the reason for the slow increasing usage of memory.
i there a way i can create something like a memory dump? I’m willing to share this with the DEVs, in case it might be helpful.
Just a little update, i have been watching mem usage while uploading a bunch of Photos from my mobile, it started and kept at a low value, so this action seems to be not forcefully related or not related and all.
however 3 days later, the memory usage has already gone up to 2,9 GB or ~25%
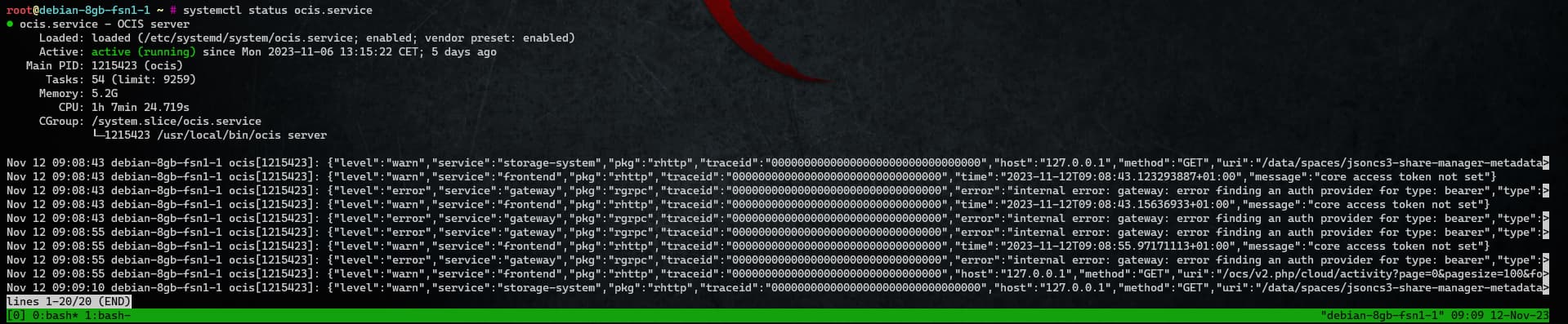
systemctl status ocis.service
● ocis.service - OCIS server
Loaded: loaded (/etc/systemd/system/ocis.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2023-11-01 12:43:44 CET; 3 days ago
Main PID: 1036462 (ocis)
Tasks: 43 (limit: 9259)
Memory: 2.9G
CPU: 31min 21.401s
CGroup: /system.slice/ocis.service
└─1036462 /usr/local/bin/ocis server
I can often see this error in the journal, but accoring to my google it can be ignored?
ocis[1036462]: {“level”:“error”,“service”:“gateway”,“pkg”:“rgrpc”,“traceid”:“00000000000000000000000000000000”,“error”:“internal error: gateway: error finding an auth provider for type: bearer”,“type”:>
Hey, thanks for your patience and creativity to work around on this.
But it is also clear: A mem leak, even if small, is a completely not acceptable situation, and we are very dedicated to fix that, once further information would be available. So whenever new info is available, please do not hesitate to share.
I am experiencing a similar issue using OCIS 4.0.5 (latest at the moment).
I just configured OCIS bare metal on my Raspberry PI 4 where I have already ownCloud 10. My idea is testing it before migrating to it from ownCloud 10.
OCIS is accessible via reverse proxy (HTTPS on port 8443), whereas ownCloud is accessible via HTTPS on port 443.
However, when I rclone the data from ownCloud 10 to OCIS (using webdav from the command line, localhost to localhost), I see the excessive memory consumption of the ‘ocis server’ just after a few minutes of transferring the data.
It gets so bad that I have to kill the transfer as the server becomes unusable even via ssh.
OCIS is configured as per the documentation at: https://doc.owncloud.com/ocis/next/depl-examples/bare-metal.html#introduction.